Building an iOS app that detects Yoga poses
Using Vision, CoreML, and SwiftUI

Over the past few years — Apple has made tremendous improvements in the field of ML and Cameras both on the hardware and software end. We’ve noticed more and more Apple devices come with a dedicated neural engine, a special processor that makes machine learning models really fast, and with the iPad Pro and iPhone 12 Pro coming with LiDAR technology — it is evident that Augmented Reality and Computer Vision are also on the forefronts of technological innovation.
Last Year at WWDC 2020, Apple introduced new APIs in the Framework that allows the ability to detect body and hand pose and also added the ability to create an action classifier ML model using CreateML (a Mac utility app that helps us create ML Models using data without necessarily requiring an ML background). With these 2 new features, it’s been easier than ever to use the ability to detect human body poses in iOS and iPadOS.
Over the pandemic, our lives have changed drastically and quarantine has forced us to stay indoors cooped up within our homes. During these times, I found myself doing lots of Yoga🧘 and it has been vastly beneficial for me both mentally and physically. And after seeing the new advancements in Vision and CoreML, I thought it would be cool to build an app that detects various Yoga Poses. Before we get into building the simple yoga pose recognition app. Let’s get down to the basics.
What is CoreML?

Core ML is the foundation for domain-specific frameworks and functionality. Core ML supports Vision for analyzing images, Natural Language for processing text, Speech for converting audio to text, and Sound Analysis for identifying sounds in audio. Core ML itself builds on top of low-level primitives like Accelerate and BNNS, as well as Metal Performance Shaders.
How to train a model using CreateML?

CreateML is a nifty tool built by Apple that makes it extremely easy and effortless to create ML models within minutes. In our example, where we want our model to be able to recognize yoga poses — we need an action classifier that can detect human actions in a video. For this, We need to categorize the poses that we need to detect using an ML model. For the sake of simplicity, let’s start with 2 poses: Mountain Pose and Plank. To be able to train an action classifier — we need a few videos about mountain pose and plank pose.
Once we have the videos segregated into 2 folders: MountainPose and Plank we can use them as training data to train our model. The folder titles will act as the label for the models to associate the recognition probabilities with. There are some parameters that we can set to fine-tune the model — `Action Duration` represents the length of the action that we are trying to recognize. In our case, a yoga pose is held at least for one second so our action duration will be 1 second.
Once all the video files are selected and parameters set, you can press the Train button and start training a new ML model. Once the model is created, the Output tab has options to export it into a file that can later be imported into the App for use.
How is this going to work?
At this point, we must have our model ready. But before we get into coding let’s plan the architecture out and imagine how the separation of concerns will take place. We can imagine the app that performs live camera recognition to have a camera screen that’s connected to a recognizer module that checks the camera feed and performs some analysis on it and shows the data around the camera screen.
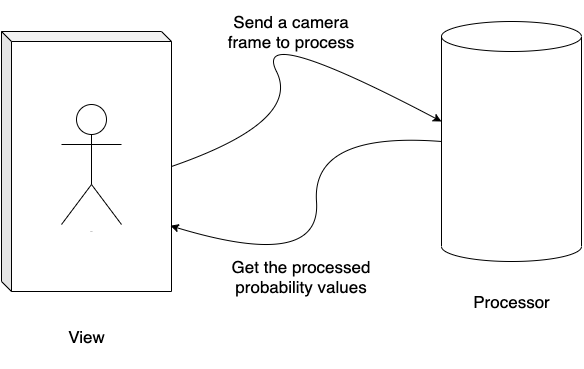
At the very least 2 major components work together to make the Live Prediction possible. Let’s talk about the Processor Module first. This processor module has 2 main responsibilities — collect frames and process them to get body poses and then pass those body poses into the ML model to decipher what pose it might be.

VisionProcessor
Uses Vision to detect body poses, CoreML to decipher what yoga pose it is.
Let's start by Setting up Vision and Pose Recognizer. According to the diagram above — we need to be able to parse each captured BufferFrame for any poses. For us to be able to analyze the buffer frame we need to have a Vision request configured and a sequence handler that handles the requests.
The instance properties: requests — which is a collection of vision requests and sequenceHandler — an instance of the VNSequenceHandler that’s injected help us with that. At this point our requests are empty to let's start by adding a method that configures our request and adds it to the list of requests that need to be performed as below:

Now that we have the instance properties, we can need to write a function that is called to analyze a frame using the sequence handler. The following function is the function that will be called from the cameraSessionDelegate callback to perform vision analysis.

Once the request is executed, the function completes with body Pose Observations. We need these body pose observations for 2 purposes — one, to draw the points on the screen, two, to collect the observations so that we can use them as input into the ML model to make predictions. The following function processObservation — normalizes the points according to the view bounds so that they can be drawn on the screen.


Now that we have built a pipeline for the Vision Processor — from setting up vision requests, adding sequence handler and writing a function that handles processing each frame and also generating CGPoints that can be laid on the screen. We need to store the collection of these [VNBodyPoseObservation] we can then pass it into our Model to make a deduction. But Before that let’s talk about our Pose Recognizer that used the ML Model to make Yoga Pose deductions.
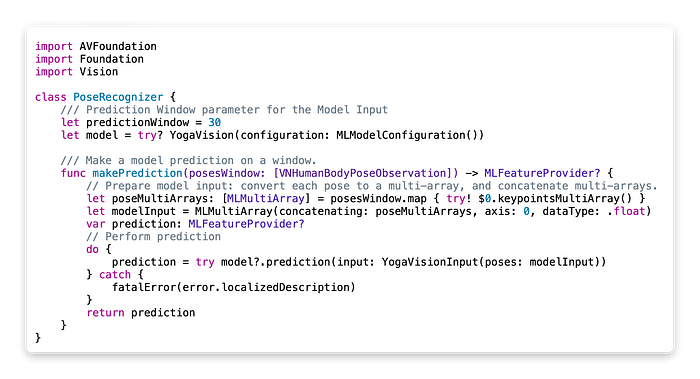
The Pose Recognizer is a class that handles all the ML aspects of Yoga Vision. You can either inject this PoseRecognizer into your Live Recognizer where all the vision requests happen or inherit your Live Recognizer from it. The Live Recognizer contains a function called makePrediction that takes the [VNBodyPoseObservation] uses the keypointsMultiArray() API call and makes a model input and passes it through the model.
Once we have enough VNBodyPoseObservation according to the prediction window of the model, we can show the model deduction probabilities on the screen. And there we go, that’s the basic logic flow of how we can build a real-time yoga pose detector.
There are tons of optimizations that can be done to improve this flow: Improving the Model by training on larger data schemes, Using Semaphores to ensure that processing happens on the single thread leading to performance optimizations… to name a few.
Where do you go from here?
- Feel free to check out the Github Repository at https://github.com/mayankgandhi/YogaVision to learn more specifics about the UI is implemented and also how a Dependency injection resolver is used with scopes to ensure separation of concerns
- Other Resources: Detect Body and Hand Pose with Vision talk at WWDC 2020 serves as a great starting point to learn about the new Vision APIs and their capabilities https://developer.apple.com/videos/play/wwdc2020/10653
